Wir freuen uns auf die kommende DHd 2020 in Paderborn, auf der die folgenden Beiträge aus Stuttgart zu hören sein werden:
Vorträge:
Marcus Willand, Benjamin Krautter, Janis Pagel, Nils Reiter:
Passive Präsenz tragischer Hauptfiguren im Drama
Mittwoch, 04.03., 14:00 Uhr (Session: V9 Dramenanalyse)
Benjamin Krautter:
Distinktive Eigenschaften im deutschsprachigen Drama
Mittwoch, 04.03., 14:30 Uhr (Session: V9 Dramenanalyse)
Nathalie Wiedmer, Janis Pagel, Nils Reiter:
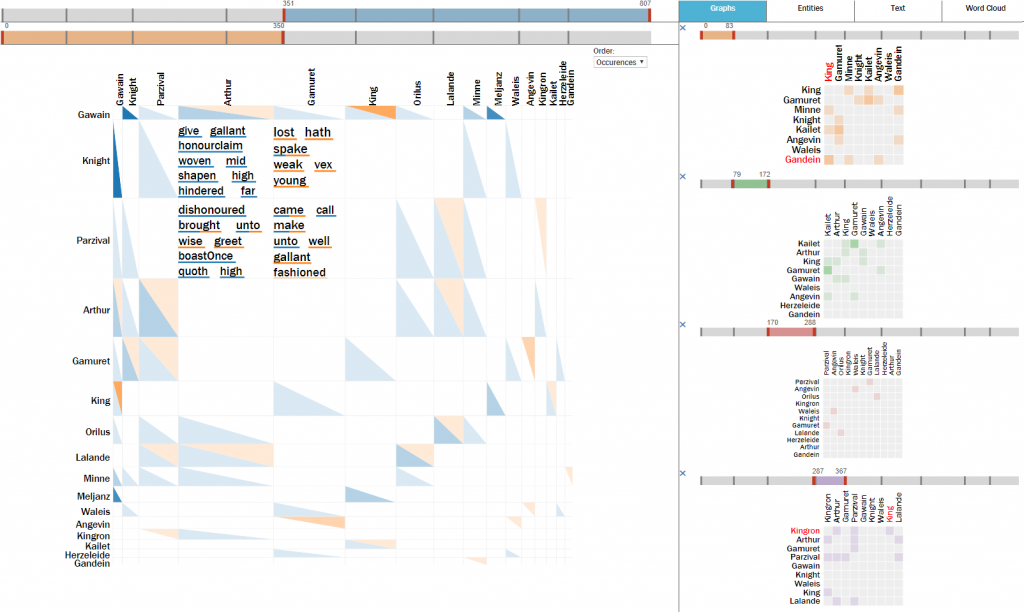
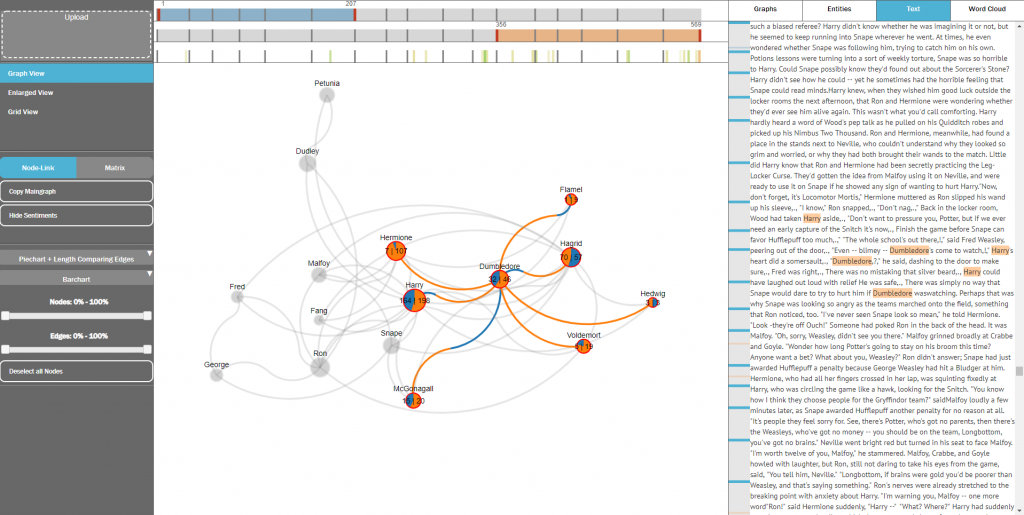
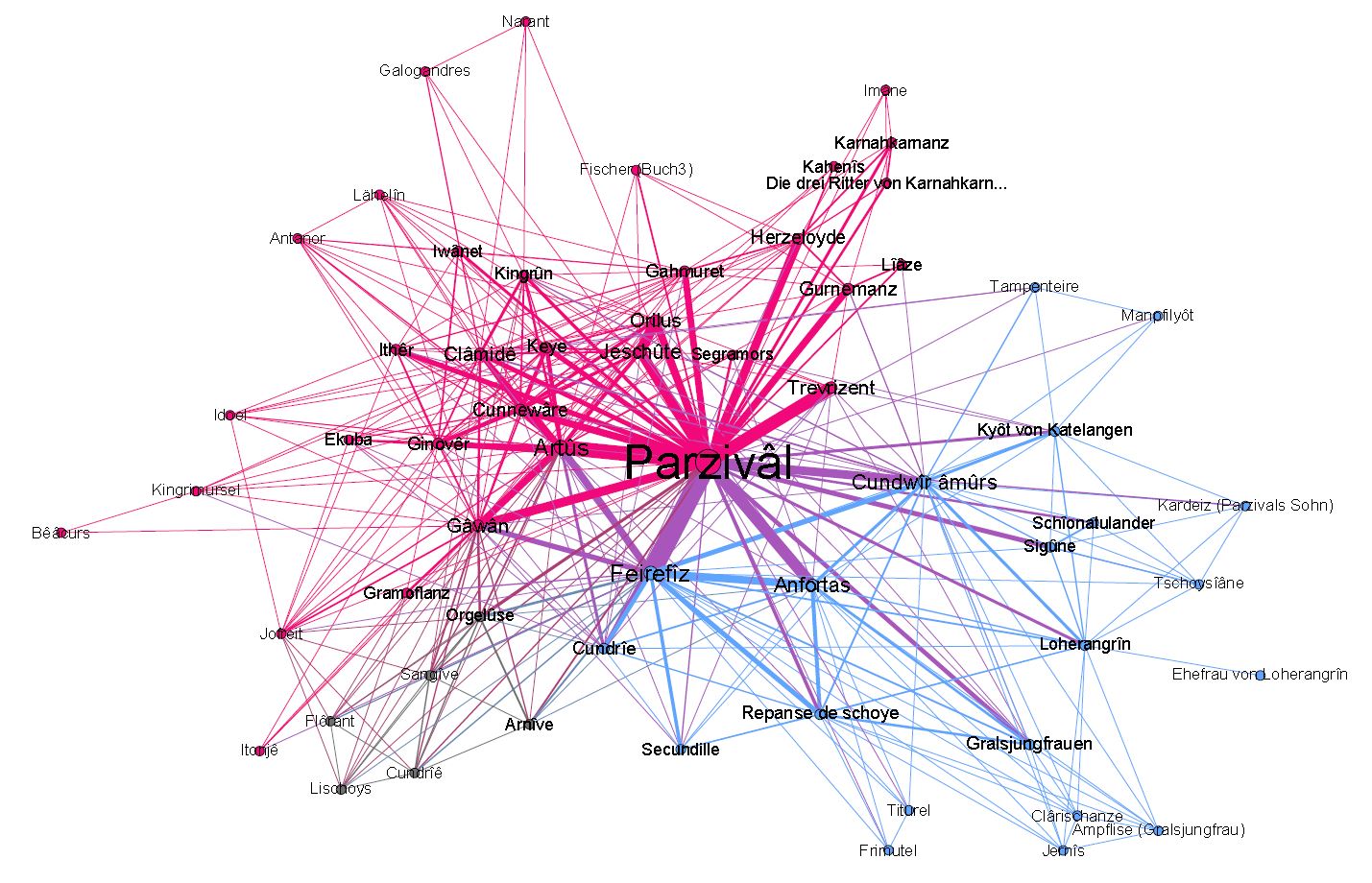
Romeo, Freund des Mercutio: Semi-Automatische Extraktion von Beziehungen zwischen dramatischen Figuren
Jonas Kuhn, Axel Pichler, Nils Reiter, Gabriel Viehhauser:
Textanalyse mit kombinierten Methoden – ein konzeptioneller Rahmen für reflektierte Arbeitspraktiken
Donnerstag, 05.03., 09:00 Uhr (Session: V12: Theorien der Textanalyse)
Rostislav Tumanov, Gabriel Viehhauser, Alina Feldmann und Barbara Koller:
Spielräume modellieren. Eine digitale Edition von Giovanni Domenico Tiepolos Bildzyklus Divertimento per li Regazzi auf der Grundlage von CIDOC CRM.
Donnerstag, 05.03., 10:00 Uhr (Session: V11 Innovationen in der Digitalen Edition)
Toni Bernhart:
As a Hobby at First. Künstlerische Produktion als Modellierung
Donnerstag, 05.03., 11:30 Uhr (Session: V13: Text / Theorie in Vergangenheit und Zukunft)
Workshops:
Gerhard Kremer, Kerstin Jung:
Maschinelles Lernen lernen: Ein CRETA-Hackatorial zur reflektierten automatischen Textanalyse
Dienstag, 03.03., 09:00-12:30 Uhr
Nora Ketschik, Benjamin Krautter, Sandra Murr, Janis Pagel, Nils Reiter:
Vom Phänomen zur Analyse – ein CRETA-Workshop zur reflektierten Operationalisierung in den DH
Dienstag, 03.03., 13:30-17:00 Uhr
Poster:
Mona Ulrich, Jan Hess, Roland Kamzelak, Heinz Werner Kramski, Kerstin Jung, Jonas Kuhn, Claus-Michael Schlesinger, Gabriel Viehhauser, Björn Schembera, Thomas Bönisch, Andreas Kaminski:
Science Data Center SDC4Lit
Panel:
Julia Nantke, Manuel Burghardt, Nils Reiter, Regula Hohl Trillini, Ben Sulzbacher, Johannes Molz, Axel Pichler:
Intertextualität in literarischen Texten und darüber hinaus
Freitag, 06.03., 11 Uhr (Panel 6)