Page Contents
Im Kontext des Centrums für reflektierte Textanalyse entwickeln wir Werkzeuge, um die textbasierte Analyse der für uns relevanten Forschungsfragen zu unterstützen. Einige dieser Werkzeuge stellen wir hier vor.
CRETAnno
Die im Rahmen von CRETA entwickelte Plattform CRETAnno besteht aus unterschiedlichen Modulen im Front- und Backend. Das Frontend wurde für die webbasierte Verwendung spezifiziert, damit von jedem internetfähigen Rechner ein unkomplizierter Zugang zu den Forschungsdaten im Projekt möglich ist. Ein Teil des Backends ist WebService-basiert und bietet neben der Benutzer- und Datenverwaltung Module für maschinelles Lernen (ML).
CRETAnno wird hauptsächlich zum Annotieren von Textstellen eingesetzt. Dies geschah bisher auf unterschiedlichen Ebenen: Entitäten, Erzählstruktur und Ortssegmenten. In Kombination mit dem ML-Backend wurde das Annotationsmodul um eine semi-automatische Komponente erweitert – so konnte die Annotationsarbeit entscheidend beschleunigt werden. 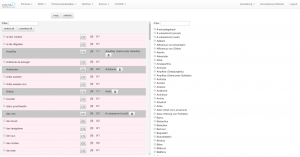
Ein weiteres Modul erlaubt interaktiv Personen-Entitäten zu disambiguieren und auf die jeweilige Figurenliste abzubilden. Auch hier wird das ML-Backend zur semi-automatischen Unterstützung eingebunden. Durch diese Zuweisungen können komplette Figurennetzwerke in einem Graph-Format exportiert und z.B. mit Gephi analysiert werden.
rCAT
Das Reporting Tool for Relational Visualization and Analysis of Character Mentions in Literature ist ein Programm zur Visualisierung von Figurennetzwerken 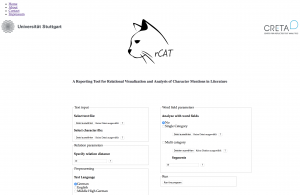 aus literarischen Texten, das auf einem Webserver als Online Demo zur allgemeinen Verfügung bereitsteht. rCAT nimmt Parameter zur Netzwerkextraktion entgegen und erzeugt Berichte im PDF-Format, in denen die Netzwerkdarstellung mit Statistiken und Wortwolken angereichert wird. Durch die Verbindung von Netzwerkextraktion, Visualisierung und Auswertung geht es deutlich über reine Grafik-Toolkits hinaus und hat gegenüber einem interaktiven Toolkit die Vorteile der Reproduzierbarkeit und direkten Weiterverwendbarkeit.
aus literarischen Texten, das auf einem Webserver als Online Demo zur allgemeinen Verfügung bereitsteht. rCAT nimmt Parameter zur Netzwerkextraktion entgegen und erzeugt Berichte im PDF-Format, in denen die Netzwerkdarstellung mit Statistiken und Wortwolken angereichert wird. Durch die Verbindung von Netzwerkextraktion, Visualisierung und Auswertung geht es deutlich über reine Grafik-Toolkits hinaus und hat gegenüber einem interaktiven Toolkit die Vorteile der Reproduzierbarkeit und direkten Weiterverwendbarkeit.
Automatische OCR-Nachkorrektur
Umfangreiche digitale Korpora, die interessantes Textmaterial zur Beantwortung relevanter Forschungsfragen aus den Geisteswissenschaften enthalten, sind nur eingeschränkt verfügbar. Archive und einzelne Forscher arbeiten daran, diesen Zustand zu verbessern, indem sie mithilfe von OCR (Optical Character Recognition) Text aus Büchern digital verfügbar machen. Die Qualität des erkannten Textes ist jedoch stark von dem Originaltext und der jeweiligen Schriftart abhängig. Um den manuellen Nachkorrekturschritt, der eine zuverlässige Textgrundlage sichert, zu erleichtern, haben wir eine Pipeline entwickelt, die textspezifisch und automatisch OCR-Text nachkorrigiert und die Ergebnisse zur abschließenden manuellen Korrektur in einem Format bereitstellt, das von einem existierenden Tool für diesen Zweck gelesen werden kann. Im Projekt nutzen wir diese Pipeline für die Erstellung des Wertheriadenkorpus.
Wortartenerkennung für das Mittelhochdeutsche
Als Teilprojekt von CRETA steht von Seiten der Mediävistik die automatische Analyse mittelalterlicher Literatur im Mittelpunkt. Im Vergleich zu den anderen Teilprojekten herrscht für das Mittelhochdeutsche allerdings ein Mangel an automatischen Verarbeitungstools vor, die die Grundlage einer solchen Analyse darstellen. Mit einem Verfahren, das eine umfangreiche lexikalische Resource nutzt, um Trainingsmaterial zum Trainieren eines Wortartenerkenners zu erstellen, verbesserten wir diese Situation für das Mittelhochdeutsche. Auf Grundlage der Mittelhochdeutschen Begriffsdatenbank trainierten wir ein Modell für den vielverwendeten TreeTagger, einen automatischen Wortartentagger. Die Abstriche in der Datenqualität, die aus der automatischen Erstellung der Daten resultiert, wird hierbei durch die Menge der verfügbaren Text ausgeglichen. Das entsprechende Modell für den TreeTagger steht zum Download bereit. Darüber hinaus wird der Wortartenerkenner als Online Demo angeboten.
Sprachidentifizierung und Wortartenerkennung für gemischte Texte
Code-Switching wird oft als ein Phänomen gesprochener Sprache beschrieben, geht aber sprachhistorisch weiter zurück und ist vor allem auch in religösen Texten aus dem Mittelalter zu finden. In unserer heutigen multikulturellen Gesellschaft scheint es auch im Bereich der natürlichen Sprachverarbeitung unumgänglich, sich damit zu beschäftigen. Wir haben ein Sprachidentifizierungssystem und einen Wortartenerkenner für Lateinisch-Mittelenglisch gemischte Texte entwickelt. Zu diesem Zweck haben wir Daten mit Sprach-IDs und Universal POS-Tags annotiert. Als Klassifikator trainierten wir einen Conditional Random Field Klassifikator für beide Teilaufgaben, welcher Gebrauch von Features macht, die vom TreeTagger generiert werden. Das System ist als Online Demo verfügbar.
Visueller Annotationsvergleich
Textannotationen können Skalierungsschwierigkeiten auf mehreren Ebenen bereiten, etwa wenn mehrere Annotatoren sehr lange Texte mit komplexen Annotationen versehen. Auf diesem komplexen Datenbestand kann nun eine Reihe anspruchsvoller Aufgaben anfallen, wie etwa die Bereinigung fehlerbehafteter Annotationen oder die Exploration von Textstellen, an denen unter den Annotatoren starke (Un-)Einigkeit herrscht oder von Strukturen, die sich aus dem Zusammenwirken verschiedenartiger Annotationstypen ergeben. Zur Unterstützung dieser Aufgaben stellt dieses webbasierte, visuelle Explorationswerkzeug eine Reihe von Aggregationsstufen und Interaktionsmöglichkeiten zur Verfügung, mit denen ein rascher, kontinuierlicher Übergang zwischen Nah- und Fernsichten auf lange, komplex annotierte Texte ermöglicht wird; auf jeder Stufe lassen sich dann etwa Uneinigkeiten oder eine Verschränkung der Visualisierung mit dem Text bzw. Textaggregationen darstellen.
Visual Text Analytics for Digital Humanities (ViTA)
Dieses webbasierte Werkzeug stellt eine Reihe von Ansichten zur Inspektion und Verifikation von Annotationen zur Verfügung: Wortwolken, Plot-Ansichten und Graphvisualisierungen ermöglichen es, Entitäten, wie Personen und Orte, in narrativen Texten zu analysieren, ihre Beziehungen zu untersuchen und ihre Kontexte besser zu verstehen. Hierbei ermöglicht jede Ansicht den direkten Zugriff auf die entsprechenden Textpassagen. Dadurch können Annotations- bzw. Verarbeitungsfehler, die bei automatischer Textverarbeitung unvermeidlich sind, schnell erkannt werden. Die bedeutendste Rolle aller Ansichten spielt hier die interaktive Graphvisualisierung, die mittels eines kräftebasierten Ansatzes Entitäten als Knoten und deren Beziehungen als Kanten abbildet. Ergänzt wird diese Ansicht durch eine Fingerabdruckvisualisierung, die anzeigt, wo im Text diese Entitäten jeweils genannt werden. Diverse Filter ermöglichen eine interaktive Exploration des Graphen, und Visualisierungen der Graphinformationen in der verknüpften Textansicht heben den Kontext der Graphelemente hervor.

Visueller Vergleich von Netzwerken
Um die zeitaufwendige und komplexe Aufgabe der Analyse von Romanen zu unterstützen, bietet dieses webbasierte Werkzeug einen Überblick über die Handlung und den Figurenbestand eines Romans. Insbesondere lässt sich damit analysieren, wie sich die Figuren und deren Beziehungen über den Verlauf der Romanhandlung entwickeln. Hierzu übernimmt das Werkzeug Annotationen von (Figuren-) Entitäten und visualisiert die Entitäten als Graph – entweder als Node-Link-Diagramm oder als Matrix. Beide Darstellungsweisen sind wiederum mit einer Textansicht verschränkt, die es ermöglicht, die jeweiligen Figuren bzw. Beziehungen in ihrem Kontext zu betrachten. Filter ermöglichen eine detaillierte Exploration, und automatisch extrahierte Beschreibungen von Figuren oder Beziehungen können auf Anfrage in Wortwolken angezeigt werden. Der Hauptfokus des Werkzeugs ergibt sich aus der Möglichkeit, zwei Beziehungsnetzwerke in einem einzigen Differenzengraphen anzuzeigen, etwa Netzwerke, die sich auf zwei unterschiedliche Textsegmente beziehen oder auf zwei unterschiedliche Arten, wie „Figurenrelation“ definiert wird.
