Im Juli erscheint der open-access-Sammelband „Reflektierte algorithmische Textanalyse“, der mit einer Reihe von Aufsätzen Einblick in die interdisziplinären Arbeiten des Center for Reflected Text Analytics (CRETA) gibt. Die in CRETA entstandenen und hier veröffentlichen Arbeiten reichen von theoretischen Auseinandersetzungen mit allgemeinen komputationellen Arbeitspraktiken über die Entwicklung textanalytischer algorithmischer Methoden hin zu Anwendungen auf geisteswissenschaftliche Untersuchungsgegenstände. Dabei legen sie ein besonderes Augenmerk auf die Nachvollziehbarkeit der Methoden und ihren reflektierten Einsatz auf die Analysegegenstände. Die Beiträge zeugen von den ertragreichen Synergieeffekten, die aus der interdisziplinären Ausrichtung des Projekts hervorgehen und nicht nur zu innovativen Arbeitspraktiken und Methoden führen, sondern auch in die jeweiligen beteiligten Disziplinen zurückwirken.
Insgesamt bietet der Sammelband eine theorie- wie praxisbezogene Einführung in die reflektierte algorithmische Textanalyse und kann damit anderen DH-Projekten mit ähnlicher Zielsetzung als Orientierung dienen.
Update vom 28.07.: Jetzt ist es verfügbar
Nils Reiter, Axel Pichler, Jonas Kuhn (Hrsg.): Reflektierte Algorithmische Textanalyse. Interdisziplinäre(s) Arbeiten in der CRETA-Werkstatt. De Gruyter. Erscheinungsdatum: 20.07.2020. URL https://www.degruyter.com/view/title/575959
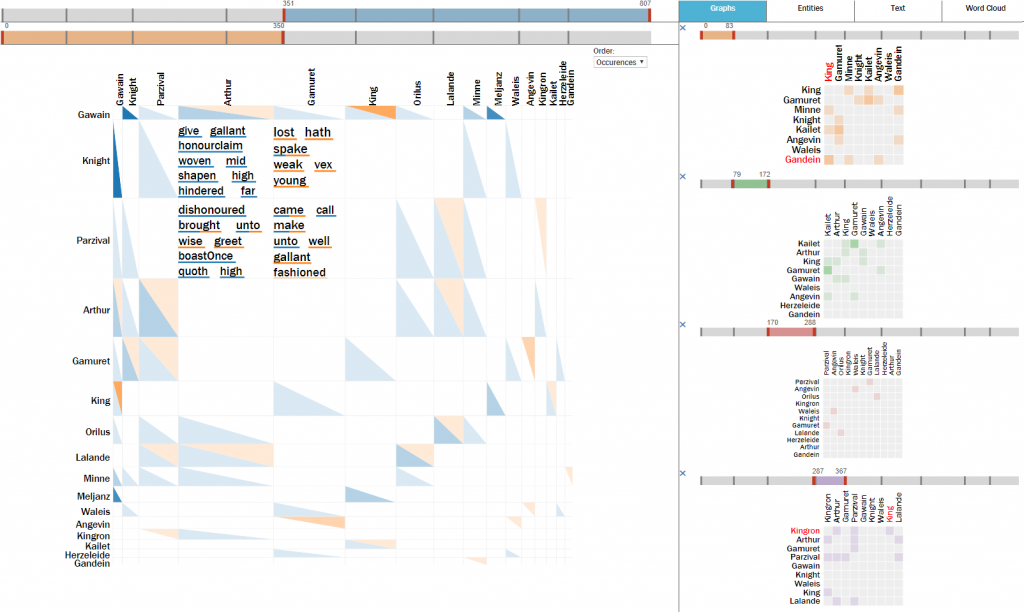
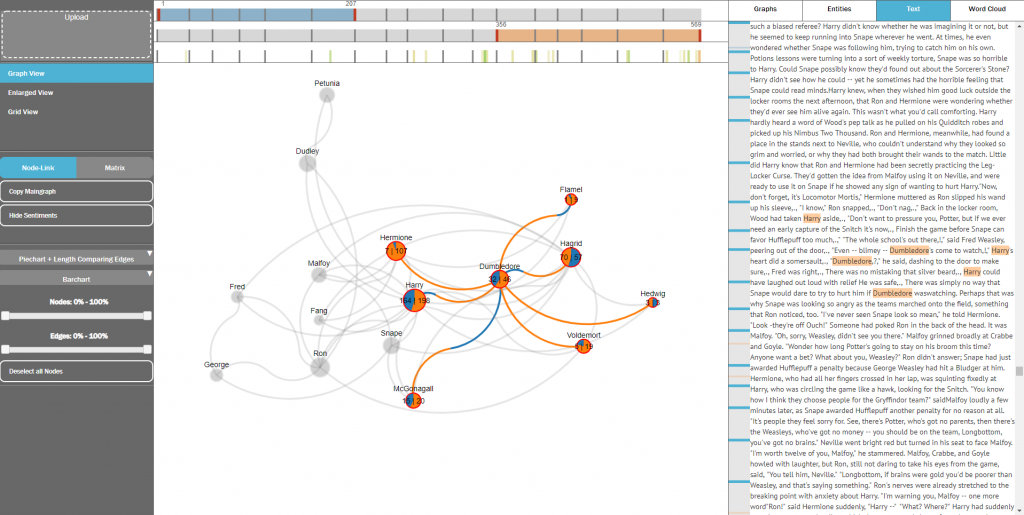
Der unter Tools und Demos von der Fachgruppe Visualisierung vorgestellte Ansatz zum „Visuellen Vergleich von Netzwerken“ wurde zur Präsentation auf der PacificVis-Konferenz (23.-26. April in Bangkok) angenommen.
Figurenbeziehungen in unterschiedlichen Textpassagen
Der Ansatz erlaubt die Analyse der Entwicklung, welche die Figuren eines Erzähltextes und deren Beziehungen über den Lauf einer Handlung nehmen. Hierzu können Graphen, welche die Figurenkonstellationen in mehreren, unterschiedlichen Textpassagen repräsentieren, in einer Reihe von visuellen Repräsentationsformen miteinander verglichen werden. Die Textpassagen selbst werden mit diesen Visualisierungen verschränkt und erlauben die Betrachtung der Figurennennungen in ihrem jeweiligen textuellen Umfeld. Beziehungen zwischen Figuren lassen sich auf Wunsch durch eine Zusammenfassung dieses Umfelds näher charakterisieren. Durch Interaktion mit den Visualisierungen lassen sich die Elemente von Graphen großer, mannigfach verknüpfter Figurenbestände derart filtern und fokussieren, dass die jeweils interessierenden Teilstrukturen augenfällig zu Tage treten.
Graph von Figurenbeziehungen mit fokussierter Teilstruktur
In zwei Anwendungsszenarien wurde demonstriert, wie sich mit unserem Ansatz eine Reihe typischer literaturwissenschaftlicher Analyseaufgaben angehen ließe. Textgrundlage der Szenarien bildeten ein mit automatisch extrahierten Figurenkonstellationen angereicherter Roman in modernem Englisch sowie ein mittelhochdeutscher Text, in welchem die Figuren manuell annotiert worden waren. Die an diesen Texten demonstrierten Aufgaben umfassten:
Bereinigung
von Fehlern des automatischen Extraktionsverfahrens.
Rasche
Erschließung der Charakteristika einer Figur und ihrer Funktion im
Handlungsgefüge.
Erkennen
von Figurengruppen, die vornehmlich in einer der selegierten
Passagen vorkommen sowie von zentralen „Brückenfiguren“,
welche diese Gruppen miteinander verbinden.
Charakterisierung
der Beziehungen, die zentrale Figuren mit anderen unterhalten.
Nachweis
der Hypothese, dass der Figurengraph sich über den Lauf einer Serie
von Passagen stark verändert.
Nachweis
der Hypothese, dass diese sukzessiven Konstellationen nur über
einige wenige, zentrale Charaktere verbunden sind.
Der Artikel von Markus John, Martin Baumann, David Schuetz, Steffen Koch und Thomas Ertl erscheint unter dem Titel „A Visual Approach for the Comparative Analysis of Character Networks in Narrative Texts“.
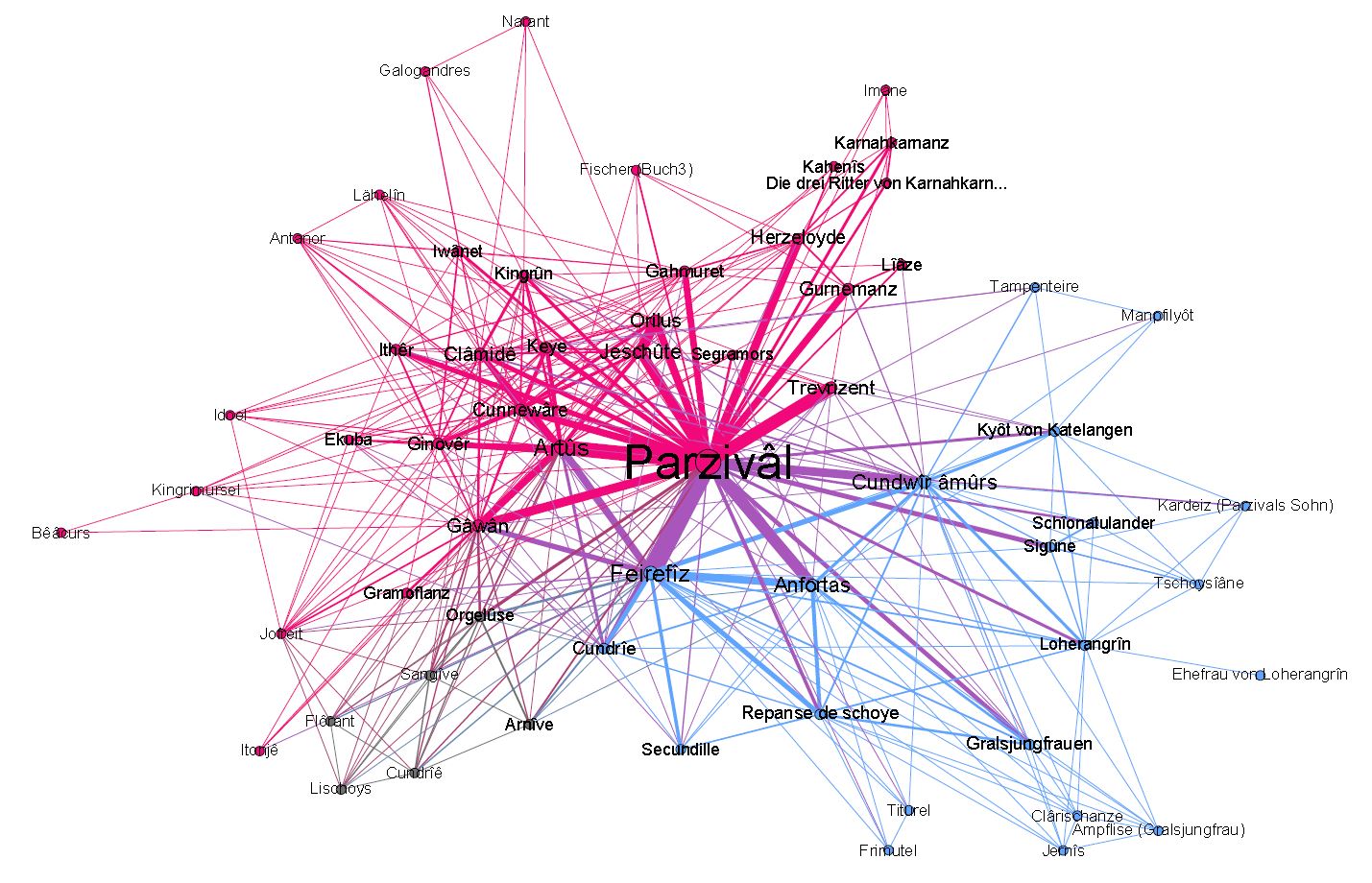
Im Themenheft „Digitale Mediävistik“ der Zeitschrift „Das Mittelalter. Perspektiven mediävistischer Forschung“ wird in Kürze ein Artikel über Soziale Netzwerkanalysen zum mittelhochdeutschen Artusroman erscheinen. Der Artikel unternimmt den Versuch, das Verhältnis von Märchen und Artusroman systematisch und methodisch neu zu bestimmen. Hierfür werden in einem ersten Schritt Merkmale des Europäischen Volksmärchens identifiziert, die in einem zweiten Schritt für die computergestützte Analyse operationalisiert und anschließend auf ein Textkorpus aus klassischen Artusromanen (Hartmanns von Aue ‚Erec‘ und ‚Iwein‘, Wolframs von Eschenbach ‚Parzival‘) angewandt werden.
Methodisch greifen wir für die Untersuchung auf das empirische Verfahren der Sozialen Netzwerkanalyse zurück, mit dem wir vor allem Aspekte der Kategorie Figur in den Blick nehmen. Auf diese Weise können wir nicht nur die Nähe der Artusromane zur ‚einfachen Form‘ des Märchens genauer bestimmen, sondern auch das Verhältnis der ausgewählten Romane zueinander differenziert betrachten. Der Beitrag zeigt, dass die vielschichtigen Ergebnisse der datengetriebenen Untersuchung eine eindeutige Interpretation verweigern und damit neue Einsichten in den bekannten Untersuchungsgegenstand ermöglichen können.
Beispiel: Netzwerk zum ‚Parzival‘ (Parzival-Partie)
Das Themenheft „Digitale Mediävistik“ mit diesem Artikel von Manuel Braun und Nora Ketschik erscheint voraussichtlich im Juni 2019.
Der sozialwissenschaftliche Forschungsschwerpunkt veröffentlichte kürzlich einen neuen Methodenartikel. Darin reflektieren wir, welchen grundsätzlichen methodischen Herausforderungen die theoriegeleitete sozialwissenschaftliche Forschung begegnet, wenn sie ihre Arbeit im Sinne der in den Sozialwissenschaften etablierten Gütekriterien gut machen will.
Wir identifizieren drei grundsätzliche Barrieren: Erstens bereitet es immer noch einen sehr hohen Aufwand, große Textkorpora zu erstellen und aufzubereiten. Zweitens ist das Problem der semantisch validen Operationalisierung komplexer geistes-, sozial- und kulturwissenschaftlicher Begriffe noch völlig unzureichend gelöst. Drittens erlauben viele der für linguistische Fragestellungen designten Tools kaum eine sozialwissenschaftlich anschlussfähige Ergebnisdarstellung. Wir brauchen flexible Optionen der Datenausgabe und Visualisierung, um die mit Hilfe korpuslinguistischer Methoden generierten Daten zur vorhandenen Forschung unseres Faches in Beziehung setzen zu können. Für alle Herausforderungen gilt, dass es hierfür keine „one size fits all“-Lösungen geben kann, weil aus der Perspektive unterschiedlicher wissenschaftlicher Forschungsfragen unterschiedliche methodische Entscheidungen zu treffen bleiben.
 Im Juli erscheint der open-access-Sammelband „Reflektierte algorithmische Textanalyse“, der mit einer Reihe von Aufsätzen Einblick in die interdisziplinären Arbeiten des Center for Reflected Text Analytics (CRETA) gibt. Die in CRETA entstandenen und hier veröffentlichen Arbeiten reichen von theoretischen Auseinandersetzungen mit allgemeinen komputationellen Arbeitspraktiken über die Entwicklung textanalytischer algorithmischer Methoden hin zu Anwendungen auf geisteswissenschaftliche Untersuchungsgegenstände. Dabei legen sie ein besonderes Augenmerk auf die Nachvollziehbarkeit der Methoden und ihren reflektierten Einsatz auf die Analysegegenstände. Die Beiträge zeugen von den ertragreichen Synergieeffekten, die aus der interdisziplinären Ausrichtung des Projekts hervorgehen und nicht nur zu innovativen Arbeitspraktiken und Methoden führen, sondern auch in die jeweiligen beteiligten Disziplinen zurückwirken.
Im Juli erscheint der open-access-Sammelband „Reflektierte algorithmische Textanalyse“, der mit einer Reihe von Aufsätzen Einblick in die interdisziplinären Arbeiten des Center for Reflected Text Analytics (CRETA) gibt. Die in CRETA entstandenen und hier veröffentlichen Arbeiten reichen von theoretischen Auseinandersetzungen mit allgemeinen komputationellen Arbeitspraktiken über die Entwicklung textanalytischer algorithmischer Methoden hin zu Anwendungen auf geisteswissenschaftliche Untersuchungsgegenstände. Dabei legen sie ein besonderes Augenmerk auf die Nachvollziehbarkeit der Methoden und ihren reflektierten Einsatz auf die Analysegegenstände. Die Beiträge zeugen von den ertragreichen Synergieeffekten, die aus der interdisziplinären Ausrichtung des Projekts hervorgehen und nicht nur zu innovativen Arbeitspraktiken und Methoden führen, sondern auch in die jeweiligen beteiligten Disziplinen zurückwirken.